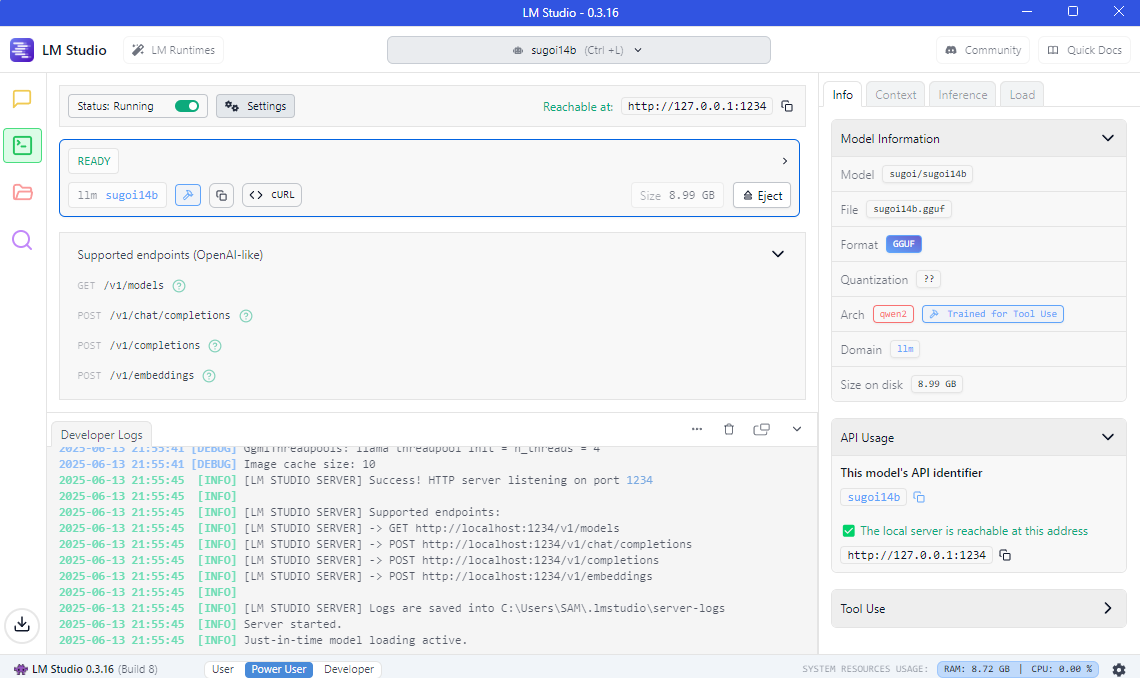
LM Studio with Sugoi LLM 14B/32B

Loading Sugoi14B/32B on LM Studio
Download Required Files
- Download Sugoi14B or Sugoi32B model files in GGUF format. Download Link: https://huggingface.co/sugoitoolkit/Sugoi-14B-Ultra-GGUF
- Download and install LM Studio from: https://lmstudio.ai/
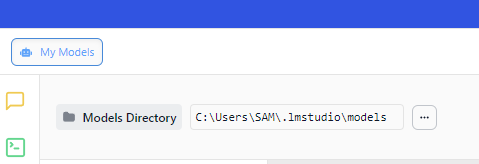
Model Placement
- Move the downloaded model files to LM Studio's model folder. You can find this directory path within the LM Studio interface. Typically:
C:\Users\<username>\.lm-studio\models
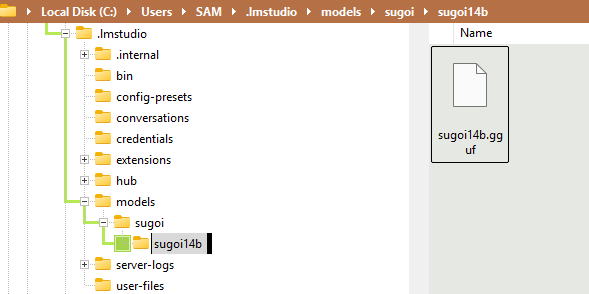
- Suggested folder structure:
~/.lmstudio/models/
└── sugoi/
└── sugoi14b/
└── sugoi14b.gguf
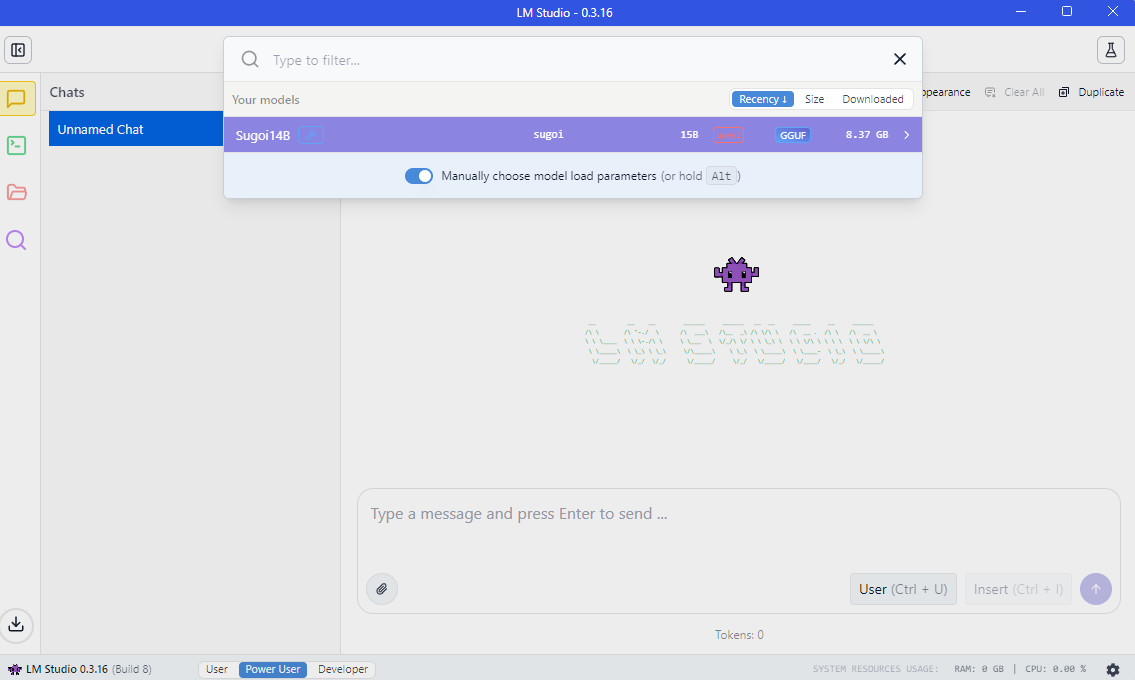
Loading the Model
- After placing it in the models folder, sugoi model will appear in the list of available models within LM Studio.
- Select and load the model.
Settings (default)
- Default settings: Context Window Size: 4096 – This is the maximum number of tokens the model can consider at once. A larger size allows for longer input context.
- Temperature: 0.7 – Controls randomness; lower values make outputs more focused and deterministic. Some users like 0.3.
- Top P: 0.9 – Used in nucleus sampling; the model considers the smallest set of top tokens whose probabilities sum to 90%. Works together with top-k. A higher value (e.g., 0.95) will lead to more diverse text, while a lower value (e.g., 0.5) will generate more focused and conservative text. (Default: 0.9)
- Top K: 40 – Limits sampling to the top 40 most likely next tokens. Reduces the probability of generating nonsense. A higher value (e.g. 100) will give more diverse answers, while a lower value (e.g. 10) will be more conservative.
- Repeat Penalty: 1.1 – Penalizes repeated phrases to reduce repetition; 1.0 means no penalty.
- Layer GPU: 14b 49 / 32b 65 – Refers to how many transformer layers are offloaded to the GPU; maximum is 49/65, so this uses full GPU acceleration but even at lower it is not too bad of waiting time when used with streaming output.
- Note: Do experiment with available options based on your hardware capability.
Running the Model
- Click the run toggle or press
Ctrl+R - Model will run locally on:
http://localhost:1234 - Accessible via OpenAI-compatible APIs